Apple built iCloud to store billions of databases
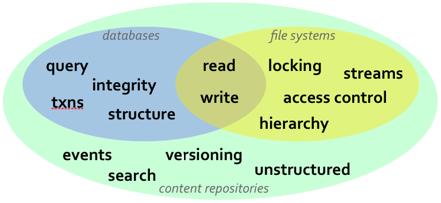
497 points by gempir 1 year ago | 190 comments- tombert 1 year agoSadly I never got to work on this when I was at Apple (interviewed for it though!), but hearing about this a few years ago sort of made me realize something that should have been obvious: there’s not really a difference between a database and a file system.
Fundamentally they do the same thing, and are sort of just optimizations for particular problem-sets. A database is great for data that has proper indexes, a file system is great for much more arbitrary data [1].
If you’re a clever enough engineer, you can define a file system in terms of a database, as evidenced by iCloud. Personally, I have used this knowledge to use Cassandra to store blobs of video for HLS streams. This buys me a lot of Cassandra’s distributed niceties, at the cost of having to sort of reinvent some file system stuff.
[1] I realize that this is very simplified; I am just speaking extremely high level.
- gumby 1 year ago> there’s not really a difference between a database and a file system. Fundamentally they do the same thing, and are sort of just optimizations for particular problem-sets.
Conceptually that is quite true, though the domain dependencies make a lot of the code end up looking quite different.
But the first true database (pre-relational!) was developed for SABRE, American Airlines' computerized reservation system, in the early 1960s. Before that tickets were issued manually and the physical structure of the desks and filing systems used to make reservations reflected the need!
Unfortunately I can't find the paper I read (back in the mid 80s) on the SABRE database but I remember that record size (which is still used today!) was chosen based on the rotational speed of the disk and seek latency. Certainly there was no filesystem (the concept of filesystem barely existed, though Multics developed a hierarchical filesystem (intended to be quite database-like, as it happens) around the same time. The data base directly manipulated the disk. I don't know when that changed -- perhaps in the 1970s?
Like I said I can't quickly find the paper on the topic, but here's a nontechnical discussion with some cool pictures: https://www.sabre.com/files/Sabre-History.pdf. A search for "American Airlines SABRE database history" finds some interesting articles and a couple of good Wikipedia pages.
- oneplane 1 year agoI think direct manipulation never went away, but the abstractions that were provided for general use were too useful to pass up for most workloads.
Some kinds of storage like cloud-scale object storage use custom HDD firmwares and custom on-disk formats instead of filesystems (±2005-era tech), we also have much newer solutions that do direct work on disks like HMR (not to be confused with HAMR or HAMMER2) where the host manages the recording of data on the disk. There are some generally available systems for that, but we also have articles like this: https://blog.westerndigital.com/host-managed-smr-dropbox/ (Which mostly focuses on SMR but this works on CMR too).
As for the record size in the DB vs. Disk attributes, that's probably not used like that anymore, but I do know that filesystem chunks/extents/blocks are calculated and grouped to profit from optimal LBA access. If you run ZFS and have it auto-detect or manually set the ashift size to make it match the actual on-disk sector size. This was especially relevant when 512e and 4Kn (and the various manufactures 'real' and 'soft' implementations) weren't reliable indicators of the best sector access size strategies.
- kevin_nisbet 1 year agoI could be wrong, but I sort of think when I learned Oracle back when I was in school (mid-2000s) supported dropping a database on a raw block device. So it's been around a long time, but would be uncommon in some tech circles.
- yencabulator 1 year agoI believe the "least proprietary" interface to this, that looks like it'll cope with both SMR rotating disks and flash, is Zoned Namespaces.
With ZNS, you have a fixed number of fixed size append-only zones, each of which can only be erased as a whole. It starts to look a lot like a typical LSM tree..
- kevin_nisbet 1 year ago
- ChuckMcM 1 year agoGood old ISAM (Indexed Sequential Access Method) before DASD (Direct Access Storage Device) took over. (Aren't you glad IBM didn't win the "name the things" contest? :-))
I'm going to guess that by "domain dependency" you're talking about how
Looks semantically different thanhandle = open("foo.txt");
So yes in that regard they certainly "feel" different, although at some point I needed a file system for an application than built a wrapper layer for sqlite that basically gave you open/read/write/delete calls and it just filled in all the other stuff to convert specialized filesystem calls into general purpose database calls.[1]err = db->exec("SELECT * from DIRECTORY where NAME = 'foo.txt';", &result);The best thing you can say about the way UNIX decided to handle files was that it forced people to either use them as is or make up their own scheme within a file itself (and don't get me started on the hell that is 'holey' files)
[1] In my case the underlying data storage was a NAND flash chip so the result you got back which was nominally a FILE* like stdio had the direct address on flash of where the bits were. read-modify-write operations were slow since it effectively copied the file for that (preserving flash sector write lifetimes)
- rbanffy 1 year agoFunny enough, DASD is now, for the first time, more accurate than "disk".
But yes. Talking to mainframe people is a bit like talking to astronauts, in that their jargon is completely impenetrable to the uninitiated.
- rbanffy 1 year ago
- rbanffy 1 year agoI love that Amdahl mainframe (page 6) with that humongous 20" CRT console.
Most likely showing a 24x80 3270 console session, with 8x16 character cells (if that much), but, still, quite awesome.
I'm not aware of any that ended up in a museum, sadly.
For those with sufficiently cool IEEE memberships, there is quite a lot about Sabre in the Annals of the History of Computing magazine archives.
https://ieeexplore.ieee.org/document/397059
https://ieeexplore.ieee.org/document/1114868
https://ieeexplore.ieee.org/document/279229, which is not about Sabre, but Air Canada's system.
If you think about it, modern IBM mainframes have a lot of weirdness about their filesystems and the concept of a file. Those machines are very alien for people who grew up on Unix.
- Scoundreller 1 year agoseems like a good time to remind people that using sci-hub might be unlawful and/or blocked in your country
- Scoundreller 1 year ago
- eep_social 1 year agoYep and this is why you still get a six character Passenger Name Record (PNR) for your flight booking.
- randomdata 1 year ago> Certainly there was no filesystem [...] I remember that record size
Sounds like a record-oriented filesystem to me.
Which comes as no surprise as there is no difference between a database and a filesystem.
- jahewson 1 year agoNot disk drives but tape drives. Most likely these:
- gumby 1 year agoSABRE was specifically disk drives, though given the capacity of drives in those days I'm sure tapes were very important (and you see a lot of them in the photos from the link I included)
- gumby 1 year ago
- lchen_hn 1 year agoAnd I thought SABRE sells printers and acquired Dunder Mifflin
- oneplane 1 year ago
- jwr 1 year ago> there’s not really a difference between a database and a file system
Having written an interface to FoundationDB in preparation to moving my app over to it, I couldn't disagree more.
Even "has proper indexes" is not something we'd agree on. In my case, for example, I am extremely happy with the fact that my indexes are computed in my app code, in my language, and that I am not restricted to some arbitrary concept of database-determined "indexable fields" and "indexable types".
Then there are correct transactions, versionstamps (for both keys and values), streaming large amounts of data, all of that in a distributed database, it's really nothing like a filesystem.
- toolz 1 year agoI'm interested in having you expand on these thoughts, so I'll play devils advocate here. I personally don't have strong opinions on the subject.
> has proper indexes
Does it matter where in the code the index lives? Are you arguing that databases don't have proper indexes or that filesystems don't? I'm not sure I'd agree with either argument.
> correct transactions
filesystems and databases have transactions, which one is "incorrect"?
> versionstamps (for both keys and values)
filesystems have timestamps, not sure what a versionstamp is but I suspect it's some domain specific name for a more general concept that both databases and filesystems utilize.
> streaming large amounts of data
many databases stream massive data and filesystems certainly do
> all of that in a distributed database
every major PaaS has some form of distributed filesystem
- drewbug01 1 year agoVersionstamps are not a simple timestamp; it’s a cluster-wide order-able unique id.
https://apple.github.io/foundationdb/data-modeling.html#vers...
- drewbug01 1 year ago
- 1 year ago
- timc3 1 year agoI suggest you write a file system, then write a database and then re-evaluate whether you still think the same way.
- toolz 1 year ago
- mike_hearn 1 year agoYou don't really need to be a clever engineer, there are pre-made implementations out there for you.
For example if you have an Oracle DB, then it has a feature called DBFS that does this already:
https://docs.oracle.com/en/database/oracle/oracle-database/2...
You can instantiate a POSIX compatible FS using database tables, and then mount them using FUSE. From there you can export it via NFS if you wish. You can also export the FS via WebDAV and thus mount it over the network using the WebDAV support built in to Windows or macOS.
If you want to work with the FS transactionally, you have to do that using PL/SQL. POSIX doesn't define APIs for FS transactions, so some other approach is needed.
Because it's stored in the DB you can use all the other features of the RDBMS too like clustering, replication, encryption, compression and if need be, you can maintain indexes over the file content.
- tombert 1 year agoAbsolutely, I was referring to the cleverness of the engineers that actually made those implementations.
Making a FUSE file system is sort of a bucket list thing I haven’t gotten around to doing yet. Maybe I should hack something together while I am still unemployed…
- divyenduz 1 year agoPlug, wrote something along these lines. It is a FUSE file system and the storage is SQLite
- hansoolo 1 year agoThanks for that one. I just started a new job, where they use only Oracle DBs and that could be useful.
- j33zusjuice 1 year agoI’m so sorry.
- j33zusjuice 1 year ago
- tombert 1 year ago
- mannyv 1 year ago"there’s not really a difference between a database and a file system"
The BeOS filesystem was basically a database.
But there are a lot of differences between a database and a file system. A better way of thinking about it is that a filesystem is just a specialized database.
From an old school, a data base is really just a collection of data. An RDBMS = relational database. A filesystem is just another kind of database. etc etc.
- mike_hearn 1 year agoBeFS wasn't really a database as we'd normally understand it. It had no transactions, for one. It only understood string and numbers as datatypes as well.
It had what was basically a normal UNIX filing system, complete with /dev, /etc and so on, and it had support for indexing extended attributes. Your app was expected to create an index with a specific API at install time, and then after that writes to the indexed xattr would update a special "index directory". The OS could be given a simple query predicate with range and glob matching, and it would answer using the indexes, including a live query.
This was neat, but you could implement the same feature in Linux pretty easily. Nobody ever has, probably because xattrs historically didn't work that well. They don't get transmitted via common network protocols and have a history of getting lost when archiving, although I think these days every archive format in real use supports storing them.
There's also the question of how it interacts with POSIX file permissions. BeOS was an aggressively single user system so just didn't care. On Linux you'd need to think about how files that you can't read are treated in the indexing process.
Multiple devices also poses problems. BeOS simply required that apps create an index on a specific device themselves. If you plugged in a USB drive then files there just wouldn't show up in search unless the files had been created by not only BeOS, but an app you had previously installed. Note that installing an app post-hoc didn't work because creating an index didn't populate it with existing files, even if they had the right xattrs.
And of course it only worked with files. If you had content where the user's conception of a thing didn't map 1:1 to files, it was useless. For example you couldn't index elements within a document this way. Spotlight can index app states and screens, which also obviously BeOS couldn't do.
So there were a lot of limitations to this.
The modern equivalent would be writing a search plugin:
https://developer.apple.com/documentation/corespotlight/maki...
The API is more complex but lets you create search results that aren't directly tied to specific filing systems.
- lsaferite 1 year agoI was about to bring up BeOS and decided to search to see if someone else had mentioned it already. Glad to know I'm not alone in remembering BeOS. :)
- randomdata 1 year ago> A better way of thinking about it is that a filesystem is just a specialized database.
Aren't all databases specialized?
- mike_hearn 1 year ago
- tw04 1 year agoMicrosoft had the same idea in the early 2000s:
- GeekyBear 1 year agoPrior to Longhorn, Microsoft had previously attempted "database as a file system replacement" as part of Cairo.
> Cairo was the codename for a project at Microsoft from 1991 to 1996. Its charter was to build technologies for a next-generation operating system
- pjmlp 1 year agoSomewhere on my parents attic there is a Windows magazine about Cairo project and all the cool things it would bring.
In both cases, Longhorn and Cairo, the only thing that survived were a bunch of COM libraries.
- pjmlp 1 year ago
- GeekyBear 1 year ago
- 0xbadcafebee 1 year agoIf anything a database is a form of filesystem, as the name filesystem comes from 'file system', a system of organizing files or records. But filesystems officially came after databases, as early databases were designed to make best use of hardware and storage devices to store and retrieve data efficiently, making it easier and faster for computers of the time to use the data. So databases were, effectively, the first filesystems.
But the distinction is pretty small. Both filesystems and databases are just wrappers around a data model. The former is primarily concerned with organizing data on a disk (with respect to space, speed, location and integrity), and the latter is primarily concerned with organizing and querying data (with respect to ease-of-use, speed and integrity).
People today seem to think relational databases were the first and only databases. But there many types of database: flat, hierarchical, dimensional, network, relational, entity–relationship, graph, object-oriented, object-relational, object-role, star, entity–attribute–value, navigational, document, time-series, semantic, and more.
The earliest filesystem, CP/M filesystem, was basically a flat database. Successive filesystems have taken on other data models, such as hierarchical, network and navigational. Since filesystems are used as a low-level interface to raw data, they didn't need more advanced data models or forms of query. On the other hand, IBM DB2, Hadoop, and Google File System are all forms of database filesystems, combining elements of both databases and filesystems.
- dboreham 1 year agoQuick note that CP/M isn't even close to the "earliest filesystem".
- dboreham 1 year ago
- jerf 1 year ago"there’s not really a difference between a database and a file system."
It depends on how abstracted you're getting. I sometimes talk about the 30,000 foot view, but in this case, I might stretch the metaphor to say that from Low Earth Orbit, there is indeed not much difference between a database and a file system. In fact, there's not much difference between those things and some function calls. You put some parameters out, you get some stuff back.
From just slightly higher one realizes or remembers, it's all just numbers. You put some numbers into the system and get some other numbers out. Everything is built out of that.
You can build a database out of functions, a file system out of a database, functions out of a file system (albeit one beyond a blob store, think /proc or FUSE rather than ext2), you can mix network streams into any of these, anything you like.
And while it's helpful to be aware of that, at the same time, you are quite into architecture astronautics at that point and you are running low on metaphorical oxygen, and while the odd insight generated from this viewpoint might help here or there, if one wishes to actually build iCloud, one is going to have to come a great deal closer to Earth or one is going to fail.
Still, in the end, it's all just numbers in response to other numbers and the labels we humans put on exactly how the numbers are provided in response to other numbers are still the map and not the territory, even in the world of programming where arguably the map and the territory are as close as they can possibly be and still be in reality.
- randomdata 1 year agoAnd, of course, if you go the other way and get closer where databases and functions are different enough to be considered different things, the filesystem is still a database. It is meant to be a database in every sense of the word.
- blago 1 year agoOne can probably say that there exists a level of abstraction where there’s not really a difference between a database and a file system. That's not a lot :-)
- randomdata 1 year ago
- paganel 1 year ago> there’s not really a difference between a database and a file system.
That was the promise of WinFS back in the day, which would have been really something had MS managed to bring it to fruition.
I still remember the hype from back then, in my opinion totally justified, too bad that things didn't come to be. I legit think that that project could have changed the face of computing as we know it today.
- mike_hearn 1 year agoThey tried to adapt SQL Server iirc but it wasn't the right approach for a desktop OS.
The issue with the filesystem-as-database concept is that unless you're doing it as a serverside thing to get RDBMS features for files, it doesn't give you much more power without very serious changes to applications.
The first problem is that databases are most useful when they index things, but files are just binary blobs in arbitrary formats. To index the contents you have to figure out what they are and parse them to derive interesting data. This is not best done by the filesystem itself though - you want it to be asynchronous, running in userspace and (these days) ideally sandboxed. This is expensive and so you don't want to do it on the critical file write path. Nowadays there are tools like Spotlight that do it this way and are useful enough.
If you don't do that then when it comes time to sell your shiny fs-as-a-db feature for upgrade dollars, you have to admit that your db doesn't actually index anything because no apps are changed to use it. Making them do so requires rewriting big parts from scratch. In that era I think the Office format was still essentially just memory dumps of internal data structures, done for efficiency, so making Office store documents as native database tables would have been a huge project and not yielded much benefit over simple text indexing using asynchronous plugins to a userspace search service.
Another problem is that databases aren't always great at indexing into the middle of blobs and changing them. Sometimes db engines want to copy values if you change them, because they're optimised for lots of tiny values (row column values) and not small numbers of huge values. But apps often want to write into the middle of files or append to them.
Yet another problem is that apps are very sensitive to filesystem performance (that's why the fs runs in the kernel to begin with). But databases do more work, so can be slower, which would make everything feel laggy.
So yeah it was a beautiful vision but it didn't work out. Note that operating systems started with databases as their native data storage mechanism in the mainframe era, and that was moved away from, because there are lots of things you want to store that aren't naturally database-y (images, videos, audio, source code etc).
- bombcar 1 year agoEven now we see many cases where "files are stored in the database" eventually migrates to "we store files on the filesystem and pointers to them in the database". I know at least a few projects that have done that migration at some point.
- yencabulator 1 year ago> Another problem is that databases aren't always great at indexing into the middle of blobs and changing them. Sometimes db engines want to copy values if you change them, because they're optimised for lots of tiny values (row column values) and not small numbers of huge values. But apps often want to write into the middle of files or append to them.
Then again, there's no such thing as overwrite on flash storage (just write-once or erase larger chunk), so maybe the next generation of storage for large objects as extents that are write-once is the way forward. Plenty of filesystems have already switched to this model.
- edgyquant 1 year agoSo basically there is a difference between a DB and an FS
- bombcar 1 year ago
- mike_hearn 1 year ago
- hiAndrewQuinn 1 year agoIt's true. One of the projects in my little "Ridiculous Enough To Work" folder is SQLiteOS, which uses a giant SQLite database as the underlying filesystem.
- hnlmorg 1 year agoI once built a FUSE file system that used MySQL as the RDBMS. The idea being a remote file system.
IIRC read only access worked well but I had issues getting write access working.
- sroussey 1 year agoSomebody else must’ve done that as well, because I remember playing around with a MySQL fuse system, with both read and write.
- sroussey 1 year ago
- hnlmorg 1 year ago
- kzrdude 1 year agoIf I understand correctly, bcachefs, that new hot filesystem, is pretty similar to a database - maybe someone knows more about this.
- Tuna-Fish 1 year agoThe on-disk layout is very similar to many modern databases, but the interface that is offered to the user is pretty much just a normal filesystem.
- lanstin 1 year agoThat's the difference - the API; as much as you can store a lot of data in either, SQL is not much like Posix. The lower level "distributed" APIs are like OS implementations of the Posix API.
- lanstin 1 year ago
- Tuna-Fish 1 year ago
- Mutttttioi 1 year agoThats how Amazon made Aurora. Move all state onto the object storage layer which is also at the end of processing (you go through the lb, than frontend, than backend, than database and land on disk).
Stateless is basically moving everything to the back.
Im pretty sure google is doing the same thing/started with it.
Also this makes it 'easily' scalable horizontal: As soon as you are able to abstract on object level, you can scale your underlying infrastructure to just handle 'objects'.
- sporkland 1 year agoWindows during the longhorn timeframe tried to create a database/FS hybrid. I think the interface differences matter in terms of optimization offered by the storage layer.
I'm sure you know all this and you were trying to make a high level point, but this old school diagram from the java content repository days shows a nice breakdown of functional differences between the two that lead to very different outcomes: https://docs.jboss.org/author/display/MODE28/images/author/d...
- dhosek 1 year agoI remember back in the 80s thinking that a file system that was organized like a relational database¹ would be a really wonderful thing. Files could live in multiple places with little difficulty and any sort of metadata could be easily applied to files and queried against.
⸻
1. I had read the original paper on database normalization over the summer and was on a database high at the time. I was young.
- rad_gruchalski 1 year agoSounds like winfs: https://www.betaarchive.com/wiki/index.php/WinFS#:~:text=Win....
- notaharvardmba 1 year agoAS/400 was doing this in the 80’s…
- rad_gruchalski 1 year ago
- 1 year ago
- fzeindl 1 year agoThe difference is that file systems need a lot of “mechanical sympathy” to account for the many quirks inside syscalls and actual physical disks.
There was a nice video about how it is really hard to implement file systems because disks just don’t do what you expect.
Databases are a layer up and assume that they can at least write a blob somewhere and retrieve it with certain guarantees. Those guarantees are a thousand hacks in the file system implementation.
- jandrewrogers 1 year agoMost non-trivial databases run on what is essentially their own purpose-built file system, bypassing many (or all) of the OS file services. Doing so is both higher performance and simpler than just going through the OS file system. Normal OS file systems are messy and complex because they are serving several unrelated and conflicting purposes simultaneously. A database file system has a fairly singular purpose and focused mission, and also doesn't have the massive legacy baggage of general purpose file systems, so there are fewer tradeoffs and edge cases to deal with.
The more sophisticated the database kernel, the more the OS is treated like little more than a device driver.
- mr_toad 1 year agoUnfortunately those mechanical sympathies related to spinning disks, and now we have SSDs that have to fake like they are spinning disks for file system compatibility and all the software that expects file systems to behave that way.
- aeyes 1 year agoWhat database are we talking about? Oracle best runs on ASM which is basically it's own filesystem.
And most journaling filesystems actually get in the way of databases which try to commit their own changelog to disk.
- jandrewrogers 1 year ago
- shuckles 1 year agoI disagree because querying is an important feature of most databases as usually conceived, so I think filesystems are only a subset of a database.
- travisgriggs 1 year agoGrep, locate, find… aren’t these all query tools for file systems?
- shuckles 1 year agoDatabase queries are a lot more complex than a pattern match search. In addition, grep et al aren’t part of the file system in both the simple sense (they ship separately) and the meaningful sense (filesystems are rarely designed to facilitate them).
- shuckles 1 year ago
- travisgriggs 1 year ago
- Vicinity9635 1 year ago>Sadly I never got to work on this when I was at Apple (interviewed for it though!), but hearing about this a few years ago sort of made me realize something that should have been obvious: there’s not really a difference between a database and a file system.
Many years back I came to the realiziation that a database is just a fancy data structure. I guess a file system is too.
- api 1 year agoAFAIK theoretically any database can be built on top of a key value store, and any transactional database on top of a key value store that also has transactions.
TiDB is an example of a distributed SQL on top of a transactional key value store called TiKV.
- daemonk 1 year agoI tend to agree. I see databases as a type of file system with more strict constraints in terms of reading/writing.
One can maybe argue that file systems are just an address book and databases are a more much complicated address book.
- randomdata 1 year agoPedantically, it is the file system that is a type of database. Traditionally, database is the low-level generic term, referring to any type of structured data stored on a computer. File system, also known as the hierarchical database, adds additional specificity, referring to a particular structuring of data. Another common one is the relational database, offering another particular structuring of data.
- naikrovek 1 year agoLDAP and the Windows registry are hierarchical databases, just like a traditional file system, so the “file system = database” makes a lot of sense to me.
- naikrovek 1 year ago
- 1 year ago
- randomdata 1 year ago
- qntty 1 year agoSee this talk for someone who tried to do this with MySQL on Linux: https://www.youtube.com/watch?v=wN6IwNriwHc
- acchow 1 year agoIt's not about the indexes. Databases support transactions and ACID properties.
File systems do not.
They have some similarity in that they both store data, but that's about it.
- embit 1 year agoIf I remember correctly the Indian Railway Passenger Reservation System was built using DEC VAX/VMS file system
- wayfinder 1 year agoAnd you start on the journey when you first learn about hash maps or binary trees.
- kennethrc 1 year agoThat was the idea behind the (ill-fated) ReiserFS, IIRC?
- mike_hearn 1 year agoReiser argued that if you optimised a filesystem for very tiny files, then many cases where apps invent their own ad-hoc file-systems-in-a-file could be eliminated and apps would become easier to read/write and more composable.
For example, instead of an OpenOffice document being a zip of XMLs, you'd just use a directory of XMLs, and then replace the XMLs with directories of tiny files for the attributes and node contents. Instead of a daemon having a config file, you'd just have a directory of tiny files. He claimed that apps weren't written that way already because filesystems were wasteful when files got too tiny.
Git is an example of a program that uses this technique, to some extent at least (modulo packfiles).
In reality, although that may have contributed, there are other reasons why people bundle data up into individual files. To disaggregate things (which is a good place to start if you want a filesystem-db merge) you also have to solve all those other reasons, which ReiserFS never did and as a project that "only" wanted to reinvent the FS, could not have solved.
Apple hit some of those issues when they tried making iLife documents be NeXT bundles:
1. Filesystem explorers treat files and directories differently for UI purposes. Apple solved it nicely by teaching the Finder to show bundle directories as if they were files unless you right click and select "Show contents". Or rather partly solved ... until you send data to friends using Windows, or Google Drive, or anything other than the Finder.
2. Network protocols like HTTP and MIME only understand files, not directories. In particular there is no standardised serialisation format for a directory beyond zip. Not solved. iLife migrated from bundles to a custom file format partly due to this problem, I think.
3. Operating systems provide much richer APIs for files than directories. You can monitor a file for changes, but if you want to monitor a directory tree, you have to iterate and do it yourself. You can lock a file against changes, but not a directory tree. You can check if a file has been modified by looking at its mtime, but there's no recursive mtime for directory trees. You can update files transactionally by writing to a temporary file and renaming, but you can't atomically replace a directory tree. Etc.
So the ReiserFS concept wasn't fully fleshed out, even if it had been accepted into the kernel. Our foundational APIs and protocols just aren't geared up for it. I've sometimes thought it'd be a neat retirement project one day to build an OS where files and directories are more closely merged as a concept, so files can have sub-files that you can browse into using 'cd' and so on, and those API/protocol gaps are closed. It wouldn't give you a full relational database but it'd be much more feasible to port apps to such an OS than to rewrite everything to use classical database APIs and semantics
- zer00eyz 1 year ago>>> 2. Network protocols like HTTP and MIME only understand files
Love when someone says something that makes my brain work!
For the most part you're spot on. HTTP has multipart messages that in theory could be extended to be composite of anything. So we could have those bundles! Oddly we can send to the server with a multipart message (forms)!!
I think that MIME is an interesting slice the OTHER way. You could store versions of the same document in a directory so HTML and JSON and XML OR a video or image in two formats and serve them up based on the MIME request.
Now if we could make one of those a multi part message...
- zer00eyz 1 year ago
- mike_hearn 1 year ago
- lupusreal 1 year agoFilesystems are hierarchical databases, as opposed to relational databases (relational is usually implicit when people simply say "database", but this wasn't always the case.)
- theGnuMe 1 year agoYes but move beyond the file system view and head straight to objects..
- MenhirMike 1 year agoIf you look up WinFS (which is a cancelled Windows file system originally intended to ship with Windows Longhorn), its basic principle is exactly that, be a database that happens to work as a file system.
Not sure why exactly it failed, I assume that it just wasn't a suitable idea at the time given that most consumer devices (especially laptops) had very slow traditional hard drives, but in the age of NVMe storage, maybe it would be worth revisiting, assuming that Microsoft is still interested in evolving Windows in meaningful ways outside of better Ad delivery mechanisms.
- bombcar 1 year agoIIRC WinFS didn't precisely fail as much as get cancelled along with Longhorn, and parts of it migrated into other projects.
Much of the consumer-facing niceties of it got implemented in search tools that track metadata separately.
- MenhirMike 1 year agoIt did fail in devliering the actual product that was intended, but yeah, they did salvage a lot of it and also AFAIK helped the SQL Server team improve a few things. So it's a bit like Intel's Larrabee (which did technically come out as a product, Xeon Phi) as well: A high profile R&D project.
- zeusk 1 year agoReFS has some learnings from WinFS
- MenhirMike 1 year ago
- bombcar 1 year ago
- hnu123 1 year ago[dead]
- gumby 1 year ago
- sporkland 1 year agoPreviously:
"FoundationDB: A Distributed Key-Value Store" [https://news.ycombinator.com/item?id=36572658]
"FoundationDB Record Layer" [https://news.ycombinator.com/item?id=18906341]
"Apple Acquires FoundationDB [https://news.ycombinator.com/item?id=9259986]
"How FoundationDB works and why it works" [https://news.ycombinator.com/item?id=37552085]
- monstrado 1 year agoI leveraged FoundationDB and RecordLayer to build a transactional catalog system for all our data services at a previous company, and it was honestly just an amazing piece of software. Adding gRPC into the mix for the serving layer felt so natural since schemas / records are defined using Protobuf with RecordLayer.
The only real downside is that the onramp for running FoundationDB at scale is quite a bit higher than a traditional distributed database.
- sidcool 1 year agoSounds cool. Any write up on this? How did you approach the design? What was the motivation to use foundation db? How much did you/your team needed to learn while doing it?
- monstrado 1 year agoNo write up, but the main reason was reusing the existing database we were comfortable deploying at the time. We were already using FDB for an online aggregation / mutation store for ad-hoc time-series analytics...albeit, a custom layer that we wrote (not RecordLayer).
When RecordLayer launched, I tested it out by building a catalog system that we could evolve and add new services with a single repository of protobuf schemas.
- sidcool 1 year agoThanks. What are the typical use cases for FDB? What can it do that, say, Cassandra can't?
- extractionmech 1 year agocan you do a concise +/- on FDB? I’ve always thought it was a fantastic architecture but never tried it. tia
- sidcool 1 year ago
- monstrado 1 year ago
- rahul342 1 year agoCurious, when you started on the your project, how did you discover and decide on using FoundationDB?
- sidcool 1 year ago
- thund 1 year agoWe gave up on iCloud for file sync, it’s broken on dozens of devices trying to “optimize” storage even when asked not to. Imagine having 4Tb (size doesn’t matter) mostly empty hard drives and not being “allowed” to keep a file copy offline, because iCloud knows better…
Now Apple is asking all file sync products like Dropbox to do the same, see Fileprovider API, breaking those as well. Really annoying
- BugsJustFindMe 1 year agoI wish they'd build iCloud to store my Time Machine backups.
- crazygringo 1 year agoAgreed.
I'm utterly baffled why my iOS backups can live in Apple's cloud but not my Mac ones.
I honestly expected them to launch it years ago. The fact they still haven't seems to mean they've firmly decided not to for some reason, but I'm totally clueless as to what the reason could be.
Especially when making more money off services is a strategic priority for the company.
- eh8 1 year agoIt isn't as polished as whatever first-party solution Apple has the potential to develop, but I just use OneDrive to restore my personal data + chezmoi to reprovision my dotfiles and it works pretty well.
About every six months I do a fire drill and completely factory reset my macbook. Takes about 10 minutes for me to go from a fresh device to one that has all my apps, data, and developer tools ready to roll. Only annoying thing you can't really automate is signing into services like OneDrive or Dropbox, but this isn't a problem if you use iCloud Drive.
- greggsy 1 year agoI’ve rebuilt using brewfiles a few times. Surprisingly painless.
- greggsy 1 year ago
- arrowleaf 1 year agoI'm mildly surprised they haven't, but the reasons seem pretty obvious. Redundancy (in offerings), storage costs, and home network upload speeds.
Redundancy because the thing most people care about backing up is media and important documents, which are likely already stored in iCloud. If you care about Time Machine back ups you probably want your whole filesystem with point-in-time restores. That's a lot more data for Apple to hang onto, for a small segment of its target market. Of course, Apple does have 2TB+ iCloud+ plans, but I would bet that the average iCloud+ subscriber is using nowhere near their limit.
- Snow_Falls 1 year agoBut apple charges for storage space? Surely people needing more storage is a huge plus for Apple. Maybe they had worries about scaling storage capacity? A company like Aple could certainly figure it out though so that seems unlikely
- crazygringo 1 year ago> Of course, Apple does have 2TB+ iCloud+ plans, but I would bet that the average iCloud+ subscriber is using nowhere near their limit.
But that's my point. To sell the 2TB plans to people who are merely on the free 5 GB or paid 50 GB plan.
And yes -- I don't even keep many files on my Mac, it's mostly in the cloud already. But if it gets lost/stolen, I want to restore all my apps and preferences the same way I do with my phone. Which is why I use Time Machine with a NAS, but it's silly to need a NAS at all. I just want to use the cloud.
- baby_souffle 1 year ago> I'm mildly surprised they haven't, but the reasons seem pretty obvious. Redundancy (in offerings), storage costs, and home network upload speeds.
I'd bet that the rigid APIs on iOS also play a huge role here. Compared to the "anywhere you have permission to `open()` on disk" approach on macOS, iOS developers don't have as many options for where/how to store data. This probably makes backup / restore an order of magnitude simpler / reliable.
- rollcat 1 year agoAt one org, we went for the highest-tier Google Drive plan (with unlimited storage), because we've had this 1% of our internal users who would really, really benefit from having it. We could only go all or nothing (and the lower tier would meet the needs of the 99%), but the cost-benefit of enabling it for everyone was still pretty good.
I suppose Apple is keeping track of these numbers as well (keep in mind they know exactly how much storage each Mac has - because you can't expand it). I am also hoping it's under intensive internal testing; the quality of their software has been going downhill for a while, no power user would ever care if they shipped another broken product.
- Snow_Falls 1 year ago
- newsclues 1 year agoPerhaps it’s because iCloud is based on AWS and Azure and the economics don’t make sense at this scale?
- crazygringo 1 year agoI'm sure Apple is getting excellent rates unavailable to you or me.
If anybody can decide to start building out massive datacenters of their own, it's Apple, and AWS/Azure know that.
And Apple just passes its rates along to the consumer. It costs what it costs.
- pulisse 1 year agoThe overwhelming majority of Apple's cloud operations are in Apple-owned data centers.
- crazygringo 1 year ago
- eh8 1 year ago
- camel_gopher 1 year agoSame here, but the “lots of Cassandra instances” approach isn’t really oriented for continuous versioning. One may notice the availability lags with the current iCloud implementation which sometimes come across as inconsistency.
- hinkley 1 year agoI don’t have that kind of bandwidth and I’m a developer.
- crossroadsguy 1 year agoIt’s the Hanlon’s at work.
- crazygringo 1 year ago
- chazeon 1 year agoWith iCloud Apple indeed handles well update conflicts in Apple Notes. I have tried to set up Obsidian or any other Markdown-based notetaking system, the sync is so often and I had to give up. Apple Notes does handle this pretty well. So I finally moved to Apple Notes.
- a_wild_dandan 1 year agoI can't do without Obsidian now. Its default graph representation of knowledge matches how my scatterbrain works. It has the creature comforts I've come to expect: simple (local) text storage, a fast command/search palette, gobs of integrations (e.g. Excalidraw for my tablet). Watching one of my knowledge vaults evolve is incredibly satisfying.[1]
Obsidian is the only note app that I've stuck with. Notion/Apple Notes/Goodnotes/etc just had excessive pain points. Obsidian "just works" for my brain. Which is a relief, since the productivity app treadmill is exhausting.
- steve_adams_86 1 year agoSomething I really appreciate about Obsidian is that they seem to be keeping the core application constrained and clearly defined. I worried they would adopt plugins into the application and have things kind of bloat out of control, but they've maintained a clear separation (even now with many plugins not working with Obsidian Publish). That can be a hard line to maintain and protect when you have paying customers and they're doing a great job sticking to what they're good at.
- chazeon 1 year agoBut how do you sync on Obsidian? Obsidian Sync?
- steve_adams_86 1 year ago
- jimmydoe 1 year agoMy experience is the opposite. I lost data twice with Apple iCloud Notes, once with its major upgrade deleted many of my notes, in the other case most my attachments became blank, I'm not on that boat ever again.
- lawgimenez 1 year agoI experienced data loss on Messages lately. But, I understand it might take some significant time since I set it to never delete forever.
- lawgimenez 1 year ago
- noname120 1 year agoI haven't had any issues with Obsidian Sync. If you attempted to synchronize your vault with iCloud I'd recommend to give Obsidian Sync a try instead.
- yosito 1 year agoHonestly, Obsidian with iCloud is so bad, that I'm afraid to pay for Obsidian Sync because half the time the errors and freezing of the Obsidian app seem like they have nothing at all to do with iCloud. It's really hard to tell, because Obsidian doesn't surface any errors, it just randomly freezes and has trouble opening files that should be there.
- noname120 1 year agoIt's just n=1 but I haven't had any random freezes or files that failed to open while using Obsidian / Obsidian Sync.
- noname120 1 year ago
- yosito 1 year ago
- a_wild_dandan 1 year ago
- redbell 1 year agoOn an unrelated note, having the original title edited by the system after being submitted without the OP being noticed really annoys me, especially when the title starts with How, Why and other terms. It just made it a little weird to read, and sometimes it breaks the meaning. I once submitted a story and had some people complaining about the title being somehow misleading. When I noticed this, it was too late to edit the title.
In the HN guidelines, you read: "Otherwise, please use the original title, unless it is misleading or linkbait; don't editorialize."
I hope this will be taken into consideration.
- CharlesW 1 year agoYour feedback may not be seen here, but the admins are supernaturally responsive to notes sent to hn@ycombinator.com.
- CharlesW 1 year ago
- alberth 1 year agoSQLite & HCTree
Given that FoundationDB is built on top of SQLite, I wonder if that team is eyeing the HCTree engine for it.
It's still in experimental mode but provides literally 10x improvement on read/writes to SQLite.
Given Apple size & scale of iCloud, that seems like a massive win for them if that engine for SQLite can mature to production stability.
https://sqlite.org/hctree/doc/hctree/doc/hctree/threadtest.w...
- georgelyon 1 year agoThey have built their own storage engine named Redwood, which has some very FoundationDB-specific optimizations (like prefix compression). Check out the "Storage Servers" section in this doc: https://apple.github.io/foundationdb/architecture.html
- rapsey 1 year agoFoundationDB only uses the b-tree implementation and even that I don't know if it is still used as they switched storage engines I think.
- pulisse 1 year agoYes, to RocksDB.
- pulisse 1 year ago
- georgelyon 1 year ago
- citizenpaul 1 year agoThis reminds me of years back when I worked in banking. I vaguely recall there was a report system called Hyperion(an?) (IBM?). The system generated a new database for every single report it made. I thought that was kinda crazy at the time but I guess it was ahead of the times.
Someone feel free to correct my memory if needed, I was not the primary person for this system or anything so I could be totally wrong.
- therein 1 year agoFunny Apple has an internal Hyperion that happens to be related to the iCloud aspect of Photos.
- therein 1 year ago
- clintonb 1 year ago…and still struggles to sync one file from my laptop to my phone.
- morelish 1 year agoYeah I gave up on it trying to sync photos. The apps on the desktop and mobile gave no indication of its state processing files. So I was waiting after a large upload for replication to occur days later and I didn’t know if it would ever complete.
- morelish 1 year ago
- jelder 1 year agoVery cool. This is the architecture that inevitably results from when you start with boxed, native, desktop software and incrementally move towards cloud based storage and collaboration. You have to be really good at doing schema changes and version migrations, because they're happening at fantastic scale without administrator intervention: not when you launch, but when each individual customer chooses to use the next version.
Quite different from a SaaS-first approach where it actually makes sense to do "customer id column"-based multi-tenancy and one-migration-at-a-time schema changes that I think most of us at less-than-Apple scales are familiar with.
- meowtimemania 1 year agoIs there any writing about these types of schema changes? It's something I run into using dynamodb.
- AtlasBarfed 1 year agoAt least with Cassandra, there are cell-level timestamps which are very useful for doing data migrations while active writes are still incoming.
You can simply mirror the writes to both systems, and then migrate the old data underneath. As long as the data transfer preserves the cell level timestamps, the read path resolves any differences and compaction will eventually clean up any duplicates. (and sstable loads will have the timestamps)
Dynamodb does NOT have cell level timestamps, I believe they have row level timestamps. How it is doing globally replicated data and mutation merges: I have no idea. It seemed like a handwave when they were announcing it about two or three years ago.
- AtlasBarfed 1 year ago
- meowtimemania 1 year ago
- zaking17 1 year agoHow would you handle schema migrations in a system like this?
- ananthakumaran 1 year agoIt depends on the layer, some of the layers might be able to take advantage of how the data is persisted. For example, if you use avro/protobuf, the decoder will handle it for you. If that's not the case, you would have to implement the migration by yourself. There is a paper[1] on this subject called "Online, asynchronous schema change in F1", which explains how to implement it.
- zaking17 1 year agothanks, i'm really enjoying that paper
- zaking17 1 year ago
- ananthakumaran 1 year ago
- oblib 1 year agoCouchDB implements a DB per user approach. Personally, I've found it much easier to use than an SQL DB for web apps I've made, but I've heard others who've always used SQL say they were frustrated with it.
- randomdata 1 year agoThe thing with SQL databases is that the API they offer is designed for low-latency operation. This is not a big deal (ideal, even!) when the application and database share the same memory space where latency is imperceptible. And when it was originally designed, that was the norm, but at some point someone got the idea that they could expose the same API over the network. The network where latency is higher. That is where things start to fall apart.
It is nothing you cannot overcome with the right hacks (what can't be overcome with the right hacks?), but it is frustrating that the network-based API wasn't designed for high latency use from the start. It didn't need to use the exact same API that was designed for a low-latency environment, but that's what we got. As SQL and web apps typically means MySQL or Postgres, that means you are apt to encounter the API design problems.
Granted, it seems there is renewed interest in SQLite to move the SQL database back to the way it was designed to be used. Which isn't surprising as all things in computing come and go in cycles. Once we round out that cycle and get back to "database on the network", maybe we can get a more well designed API meant for high latency to remove those frustrations.
- randomdata 1 year ago
- yosito 1 year agoGreat! If only I could manage which of my files stay local, and which get offloaded to iCloud I might be impressed. But it seems that iCloud likes to offload recently used files, apps and photos to make room for my massive library of old photos. It frequently makes my iPhone unusable unless I'm on wifi, and then I still have to wait for everything I want to use to re-download from iCloud.
- ultra-jeremyx 1 year agoThis sounds a lot like AWS Aurora, which (I'm simplifying here) is a database interface on top of a distributed file store, (S3).
- jahewson 1 year agoI assume you mean AWS Athena - but no this is quite different from FoundationDB. Athena separates compute from storage (it’s Presto https://prestodb.io/ under the hood). Think of it as an on-demand SQL compute cluster. FoundationDB is a traditional combined storage/compute cluster. The Record Layer does provide some ability to scale-out the higher-level aspects of querying but it’s just a client library, not a separate compute service.
- gwright 1 year agoThis is the first time I've seen it suggested that Aurora is implemented on top of S3.
This overview doesn't mention S3: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide...
- ultra-jeremyx 1 year agoThat's because I meant Athena! https://docs.aws.amazon.com/athena/latest/ug/what-is.html
Doh!
- mr_toad 1 year agoAthena is a query engine, not a data store. It’s actually built from Presto (or maybe it’s Trino now, I’m not sure).
- mr_toad 1 year ago
- ultra-jeremyx 1 year ago
- jahewson 1 year ago
- kjkjadksj 1 year agoIf only large downloads from Apple like iCloud pulls didn’t time out and you weren’t trapped in these databases as a result
- colesantiago 1 year agoDoes anybody other than Apple use FoundationDB in production?
- jwr 1 year agoSnowflake is the big well-known user, but it seems there are many smaller production users as well.
I'm planning to migrate to it. It's quite simply the best distributed database out there today.
- meowtimemania 1 year agoWould you self host foundationDB? It seems there aren't many providers.
- jwr 1 year agoYes, definitely! I have been self-hosting everything for years now, and I'm very happy. Even a three-machine bare-metal cluster has impressive computing power and is difficult to grow out of. I can't envision growing out of a five-machine cluster.
I found higher-level solutions (like AWS) to be slow, complicated and expensive, and I really can't see any reasons to use them.
- jwr 1 year ago
- meowtimemania 1 year ago
- DASD 1 year agoOpen Source Stalwart E-mail(IMAP/JMAP) server recommends using FoundationDB for distributed setup backends.
- jeffbee 1 year ago
- mk12 1 year agoSnowflake used it when I worked there and I assume still does.
- yukIttEft 1 year agoWould you mind sharing what made you quit Snowflake? (I'm considering applying there)
- yukIttEft 1 year ago
- FelipeCortez 1 year ago
- theythem 1 year agoDeno KV
- 1 year ago
- esafak 1 year agoSurrealDB
- superaking 1 year agoExoscale
- lokar 1 year agoWavefront
- jwr 1 year ago
- 1 year ago
- Y-bar 1 year ago…and still can't show which 114 images in my iCloud photo library cannot be synced.
Phone says this since many years and iOS updates back: 10365 photos synced, Mac says: 10251 photos synced.
- latexr 1 year agoIf you’re feeling adventurous, something you can try on the Mac is to trash `~/Library/Application Support/CloudDocs` and then restart the daemons by running `/usr/bin/killall bird cloudd`.
I only used that once, but it fixed all the months of odd syncing I had experienced.
- crimbles 1 year agoThis is easily fixed on the mac: https://support.apple.com/en-us/HT204967
Had the same problem and this fixed it.
- ipython 1 year agoI had a similar issue when I was trying to back up all my iCloud photos to S3 through the PhotoSync app[0]. I had about 600 photos that could not be downloaded from iCloud photos onto my iPhone. I ended up disabling iCloud Photos on the iPhone, then re-enabling it. This did end up making those photos available for download and the sync worked... it was rather nerve wracking though.
- throwaway_08932 1 year agoMom had an issue where all her iCloud photos were syncing except the ones she'd taken after they renovated the kitchen. She had photos of everything but the kitchen synced.
- koolba 1 year agoSo they’re both synced, but they’re not in sync?
Perhaps it’s a Heisenberg type situation where measuring whether a file is synced itself changes the sync status.
- troupo 1 year ago...and still can't sync read/unread and deleted status in iMessage between Mac and iOS
- latexr 1 year agoI may be misremembering, but I think the deleted status does not sync on purpose unless you have “Messages in iCloud” turned on. On the Mac it’s under System Settings > [Your Name] > iCloud > Show More Apps…
- troupo 1 year agoI have Messages in iCloud turned on, and still...
Deleted messages would disappear in Big Sur. But read status wasn't synced for unread messages
In Catalina if you delete an unread message on iOS, it will disappear on MacOS, but Messages will still have an "1 message unread" badge.
- troupo 1 year ago
- crossroadsguy 1 year agoNow sit back and wait for a million attempted interpretations on how this could be just not accepting it and that this is how it is suspected to behave. And just marking any message unread and read triggering probably some job fixing it so normal and needed step for this flawless feature to work.
You might also be told that you are supposed to delete those messages on every device and that if you expect it to work automatically then you don’t get it.
- latexr 1 year ago
- 1 year ago
- latexr 1 year ago
- throwitaway222 1 year ago2005 - We need 1 database
2010 - We need 2 databases
2015 - We need 500 databases
2020 - We need billions of databases
2025 - Prediction: We need 1 database.
- Spivak 1 year agoI mean this is pretty much your prediction, one ginormous database that creates the facade of billions of logical databases within.
- 1 year ago
- Spivak 1 year ago
- cushpush 1 year ago[flagged]
- ijhuygft776 1 year ago[flagged]
- alisonsandy 1 year ago[flagged]
{kind=link}